Python for Collaborative Drug Discovery
Introduction
AstraZeneca is one of the world's leading pharmaceutical companies. With over 54,000 employees world-wide, it provides innovative, effective medicines designed to fight cancer, provide pain control, heal infection, and fight diseases of the cardiovascular, central nervous, gastrointestinal, and respiratory systems.
Finding a new drug often takes over a decade and more than $800 million. A big problem early in the process is identifying those candidates more likely to be good drugs from the vast universe of possible molecules.
Computational chemists have developed many techniques to predict molecular properties. These can be used to evaluate the likelihood that a molecule will be stable in the stomach (for pills that are swallowed), and that it can travel through the blood stream, cross the cell membrane, and eventually be broken down and eliminated, all without being too toxic to the body.
If these computational techniques were good enough there would be no need to do actual experiments. But today's computer models cannot fully characterize a molecule's behavior in the body, nor replace the intuition of a skilled pharmaceutical chemist. Real molecules must still be tested in the laboratory to see how they react.
To save time and money on laboratory work, experimental chemists use computational models to narrow the field of good drug candidates, while also verifying that the candidates to be tested are not simple variations of each other's basic chemical structure.
Process Improvements Needed
Much of the work on drug identification actually takes place through collaboration between many research groups scattered around the world. As part of this process, experimental chemists send a list of compounds to the computational chemist, who works on the data set and sends back the results.
Historically, experimental chemists were forced to rely on computational chemists and other staff to run computer predictions. Each prediction technique required running a separate program, some commercial and others developed in-house by different groups around the company, and each program had its own set of inputs, options, configurations, and failure behaviors. An experimental chemist usually didn't have the training to work with them, which meant that the computational chemists were forced to take time out of their work on developing new techniques to run routine models.
In 2000, AstraZeneca wanted to improve this process so that experimental chemists could make better computational predictions on their own, and so that the research of the computational chemists could progress at a faster rate, and make its way into the lab more quickly.
Pierre Bruneau, a Principal Scientist at AstraZeneca, had worked on this problem while at Zeneca, which merged to form AstraZeneca. He developed a web-based interface called H2X, named after the allied navigation systems used during the second world war. H2X was based on an in-house molecular property calculator called Drone. This system used a Perl script which computed some of the simpler molecular properties by calling the appropriate prediction program, usually through a wrapper written in Perl, csh, or a domain specific control language.
Python Chosen
H2X using Drone was a successful experiment and it was used by many people. In 2001 AstraZeneca decided to develop it further and brought in Andrew Dalke as a consultant, to improve the back-end code by making it more robust, extensible, and maintainable. Andrew, a well-known advocate for Python in computational chemistry and biology, convinced the group that Python was the appropriate language for the next generation back-end, which was named PyDrone.
Python was chosen for this work because it is one of the best languages available for physical scientists, that is, for people who do not have a computer science background. Many other powerful and expressive high level languages exist, including Perl, Lisp, Scheme, Ruby, CAML, and Haskell. Of all these, Python is one of the few that is based on research into usability and the factors that make a programming language easy to learn and use. Yet Python was also designed to solve real-world problems faced by an expert programmer. The result is a language that scales well from small scripts written by a chemist to large packages written by a software developer.
Python's Error Handling Improves Robustness
The first iteration of PyDrone refactored the existing Perl code into more appropriate functions, classes, and modules while translating the code base into Python. Refactoring the Perl code without moving to Python would have produced comparable architectural results, but Python's explicit error handling and stronger type checking helped to considerably improve the code's robustness.
The current version of PyDrone uses about 20 different external binaries and scripts to predict various molecular properties. When an external program works correctly, then the output is easy to parse into the desired results. However, these programs don't always work correctly, are not fully documented, and it's often hard to determine all the possible failure cases from the outside. To compensate for this, the PyDrone developers wrote tests to anticipate as many error cases as possible, but it was impossible to rule out additional unexpected error cases after deployment.
From experience dealing with this issue first in Perl (Drone) and then in Python (PyDrone), we found that Python is better at catching many types of errors and at managing unexpected problems in a deployed application. This is a result of the way in which the two languages approach error handling in general. For example, Perl's I/O routines are quiet and failures must be checked explicitly, usually with the "or die" idiom. A conscientious programmer will always add those, but they take up space, are easy to forget, and hard to test. In contrast to this, Python functions are noisy and almost always raise an exception automatically when there is a problem in code.
After rewriting in Python, we initially thought this noisy behavior was a nuisance because Python kept raising exceptions and stopping where the old Perl code had kept on going. However, we soon found that nearly every exception indicated a previously undetected error case for which we needed to add new error handling code. Python was helping us find problem spots and preventing us from letting silent errors into our data.
One example of an error case that Python uncovered for us was caused by an external prediction program that would usually return a numerical error code but in some cases was found to return the string "error" instead. In Perl, strings and numbers are converted automatically, for example the string "123" becomes the integer 123. Unfortunately, Perl also converts non-numerical strings, such as "error", to 0. As a result of this, Drone was treating "error" as a successful return value, leading to incorrect results. Python's stronger typing uncovered the error as soon as the rare case that caused it was executed.
Another way in which Python helped us to improve our code was by its inclusion of a complete stack traceback with each exception report. We found this very useful in helping us understand the source of a problem without needing to run a debugger or add extra code instrumentation. This feature of Python was particularly helpful in remote debugging of rare cases. Andrew is in the United States and Pierre is in France. When an error occurred, Pierre's email with the traceback often contained enough information to pinpoint and fix the problem.
Adding Powerful Extensibility with Python
The next stage in PyDrone's development was to improve its extensibility. Some molecular properties depend on other properties. For example, a molecule's mass depends on its composition. The older Drone code maintained these dependencies manually with a set of 'if' statements that specified which prediction routines should be called, and in which order, during execution of an analysis. In this approach, adding new dependencies soon led to a combinatorial nightmare.
To solve this problem in Python, we developed a simple rule base which acts like a Python dictionary. It contains a data cache and a mapping from property name to prediction function. If a requested property name (the dictionary key) is in the cache, we reuse it. Otherwise, we find the associated function, call it to compute the value, store the result in the cache, and return it. The functions themselves are given a reference to the Properties manager so they can recursively request any additionally needed dependencies. To add a new prediction we register the new function in the function table -- and let the functions themselves handle the dependencies. The cache is needed because some properties are expensive to compute or are needed by many other properties.
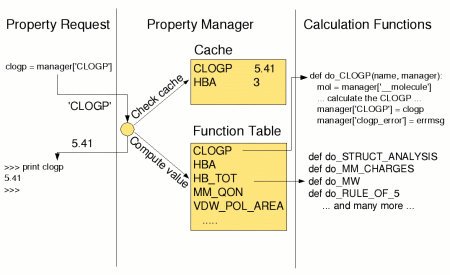
Architecture of the Property Manager Zoom in
{kind=link}
The resulting new architecture made a simple but profound difference to the project. We now have a single system that can accommodate all current and future prediction methods, that computes only the minimum needed to yield the requested results, and that is easy to understand and maintain. Before we built it in Python, several people in the company had argued it impossible to build such a system at all.
The Benefits of Python's Type System
The PyDrone architecture could have been implemented in many languages, but Python's dynamic typing made it much easier to build our Property manager. Some molecular properties are numbers, others strings, or lists and dictionaries, and still others are class instances. A statically typed language would have required extra hassle to allow a mixture of return types to be inserted into the Property manager. Even Perl, which is also dynamically typed, would have required some way to distinguish between references to a $scalar, %hash, or @list. In Python it just worked, and we could mix the data types of the keys in the Property manager dictionary without any extra effort at all. Yet, as described above, Python does at the same time provide sufficient data type checking to find many kinds of common type mismatch errors.
One of the factors that made our Property manager so successful was that Python lets user-defined types emulate the behavior of built-in types. Our Property manager acts very much like a lookup table that maps property name to value, so we designed it to emulate a Python dictionary. In Python, this is done by implementing specific special methods such as __getitem__(), __setitem__(), and so forth. By emulating a dictionary, nearly every other Python function that operates on a dictionary would work with our manager. It also made the code easier to understand and debug because the syntax and point-of-call usage fit naturally with what people expect.
Python facilitated our Property manager implementation in other ways as well. One PyDrone feature that had been requested by users was the ability to describe a new prediction using an equation based on existing properties. For example, an equation might look like:
0.34 + (0.78*CLOGP) - (0.018*HBA) - (0.015*HB_TOT) - (0.11*MM_HADCA) - (0.017*MM_QON) + (0.012*VDW_POL_AREA)
where the variables are keys in the Property manager. This was quite easy to implement in Python, and we would be hard pressed to find a language that makes it any easier. Python's mathematical expressions are almost identical to the standard form used in the sciences, so we could use Python's "eval" statement to parse and evaluate the user-defined expressions. Because our Property manager acts like a Python dictionary, it could (at least in theory) be provided directly to the eval statement as the locals dictionary used for variable lookup during expression evaluation.
As it turned out, for performance reasons, the eval() implementation in Python accepts only built-in dictionary types and not an emulated mapping type, so we had to engage in some extra trickery to make our on-demand dependency system work with equations. Nevertheless, the entire implementation was quite easy.
Results
PyDrone took about 3 months of development time, another 3 months of QA, and 3 weeks of documentation time to produce about 5,600 lines of finished Python code.
Overall PyDrone has been a wonderful success for AstraZeneca. As a result of using Python, we were able to quickly and easily develop a great tool that is both very simple to use and that adapts well to new prediction methods.
The biggest problem we've had with Python is that relatively few people at AstraZeneca use it for development. The IT group prefers either Perl (systems people) or Java (architecture people) so we occasionally get requests to rewrite parts of the project in one of those languages. Even so, we have found developers are interested in learning Python, especially when they see comparisons of development time and effort, resulting code size, and other metrics.
About the Authors
Scott Boyer is a Principal Scientist in the Enabling Science and Technology section of AstraZeneca Discovery R&D, Mölndal, Sweden. Scott received his Ph.D. from the University of Colorado, Boulder and has worked at both Pfizer and AstraZeneca in experimental mass spectrometry and NMR associated with establishing optimal 'Drug-Like Properties'. About four years ago he made the transition to the 'dark side' of computational chemistry and now heads the internal project to bring more modelling tools to bench chemists on all 10 Discovery research sites in AstraZeneca.
Andrew Dalke is the founder of Dalke Scientific Software, LLC, a software consulting and contract programming shop located in Santa Fe, New Mexico, USA. Andrew has been developing computational chemistry and biology software since 1992. His main focus is combining usability design and software engineering to develop software tools that scientists both use and enjoy. It's no wonder he likes Python so much.
Pierre Bruneau is a Principal Scientist in the Cancer and Infection Research Area of AstraZeneca Discovery, Reims, France. After studying chemistry at the Ecole Nationale Supérieure de Chimie de Strasbourg, he initially joined Organon R&D and then AstraZeneca (formerly ICI Pharma and then Zeneca) at Reims, France. After several years acting as a Medicinal Chemist, Pierre now heads the local physical chemistry and computer group of the French lab, while maintaining an interest in developing methods and tools for predicting physico-chemical properties and establishing structure-activity relationships of potential drug molecules.